Strategy Buidling
Objective
The goal is to run a backtest simulation including transaction costs and using classical alphas.
Data
Given a Matlab databse contains the following variables:
| Variable | Dimension | Definition |
|---|---|---|
| allstocks | \(1 \times n\) | contains dscode, index, name, ibes, bb, isin, industry information for each stock |
| myday | \(T \times 1\) | contains all the trading days |
| price | \(T \times n\) | adjusted close price for each stock every trading day |
| tri | \(T \times n\) | total return index |
| volume | \(T \times n\) | trading volume |
| mtbv | \(T \times n\) | market to book value ratio |
| rec | \(T \times n\) | analyst recommendation change |
| isactivenow | \(T \times n\) | trading status |
| tcost | \(T \times n\) | transaction costs |
To calculate the required variable in the portfolio construction stage, we preprocess the data in the following way:
1 | |
Risk Model
To estimate the risk level in the portfolio, we calculate the shrinkage estimator of the covariance matrix using the past year of daily returns for the active stocks in the universe. The returns are calculated with as the arithmetric returns from DataStream’s Total Return Index.
Active Stocks
The active stocks are defined as the stocks in the universe where isactivenow is equal to one on the first day of the month.
1 | |
Monthly Covariance Matrix Calculated with Past Year’s Daily Return
For every month starting from Jan 1998 to Dec 2002, using the past 12 months daily return to calculate the shrinkaged covariance matrix:
\[\begin{aligned} \hat{\beta} &= 1 - \frac{\frac{1}{T(T-1)} \sum_{t=1}^{T}{ \lvert\lvert X_t X_t' - S \rvert\rvert^2}}{\lvert\lvert S - \bar{\sigma} \mathbf{1} \rvert\rvert^2} \\ \text{with} & \\ S &= \frac1T \sum_{t=1}^{T}{X_t X_t'} \text{, sample covariance matrix}\\ \bar{\sigma} &= \frac1n \sum_{i=1}^{n}{\sigma_{ii}} \text{, shrinkage target (average variance)} \end{aligned}\]1 | |
Alphas
A weighted blend of alphas drawn from the four main categories of alphas will be used in the backtesting model. I cross-sectionally demean, standardize and windsorize every day each of these four alphas individually before blending them up with the specified weights, and I also cross-sectionally demean, standardize and windsorize every day the blended alpha afterwards.
- SHORT-TERM CONTRARIAN (TECHNICAL): the short-term mean-reversion alpha with triangular decay
- SHORT-TERM PROCYCLICAL (FUNDAMENTAL): the recommendations revision alpha
- LONG-TERM CONTRARIAN (FUNDAMENTAL): the value alpha calculated with market-to-book ratio
- LONG-TERM PROCYCLICAL (TECHNICAL): the ‘straight’ momentum alpha derived from t-12 to t-2 (11 months) of returns
To calculate the mean-reversion alpha, I incorporated the industry list.
1 | |
Optimizer
I use quadprog.m in Matlab instead of quadratic programming tools in Python in that it provides lower constraint in the variables. The scalar parameter \(\lambda\) controls turnover and the
scalar parameter \(\mu\) controls book size. The backtest simulation runs for five years from the first business day of 1998 to the last business day of 2002. The target average book size is approximately $50M long by $50M short.
The model setup is in the following:
\[\begin{aligned} \text{min}_u \frac12 u' H u &+ g' u\\ \text{Subject to } A u &\leq b \\ C u &= d\\ LB \leq u &\leq UB \\ \end{aligned}\] \[\text{With }u = \begin{bmatrix}y\\z\end{bmatrix}\] \[H = 2\mu \begin{bmatrix}\Sigma & -\Sigma\\ -\Sigma & \Sigma \end{bmatrix}\] \[g = \begin{bmatrix} 2\mu\Sigma w -\alpha +\lambda\tau \\ -2\mu\Sigma w +\alpha +\lambda\tau \end{bmatrix}\] \[A = \begin{bmatrix} R' & -R' \\ -R' & R' \\ F' & -F' \\ -F' & F' \end{bmatrix}\] \[b = \begin{bmatrix} r^*\cdot \mathbf{1} - R' w \\ r^*\cdot \mathbf{1} + R' w \\ f^*\cdot \mathbf{1} - F' w \\ f^*\cdot \mathbf{1} + F' w \end{bmatrix}\] \[C = \begin{bmatrix} \beta' & -\beta' \end{bmatrix}\] \[d = -\beta' w\] \[LB = \begin{bmatrix} 0 \\ 0 \\ \vdots \\ 0 \end{bmatrix}\] \[UB = \begin{bmatrix} max(0, min(\theta, \pi - w)) \\ max(0, min(\theta, \pi + w)) \end{bmatrix}\]| Variable | Dimension | Definition |
|---|---|---|
| \(\mathbf{x}\) | \(n \times 1\) | desired portfolio weights |
| \(\mathbf{w}\) | \(n \times 1\) | initial portfolio weights |
| \(\boldsymbol{\Sigma}\) | \(n \times n\) | covariance matrix of stock returns |
| \(\boldsymbol{\alpha}\) | \(n \times 1\) | aggregate alphas |
| \(\boldsymbol{\beta}\) | \(n \times 1\) | historical betas |
| \(\boldsymbol{\tau}\) | \(n \times 1\) | transaction costs |
Calculate Historical Betas
Use value-weighted return as market return
\[r_{stock} - r_f = (r_{mkt} - r_f)\beta + \varepsilon\]The U.S. one month T-bill rate is used as $r_f$, and $r_{mkt}$ is calculated from the value-weighted return of stock universe.
Run regression over past 12 months to get market beta for stock in month t
1 | |
Calculate Industry Dummy Matrix and Country Dummy Matrix
1 | |
Calculate maximum traiding constraint
I calculate the 1% ADV for 1-month rolling basis.
1 | |
Book Size
Maximum book size = $min(10\times \theta_i, 2.5\% \times $50M)$
1 | |
Transaction Cost for Trading Days
From the given dataset, we have the tranaction cost for every month. We need to map it to every single trading days.
1 | |
Backtest
After the preparation works for the optimizer, we can proceed to MATLAB quadprog.m
1 | |
Backtesting Result
The backtesting result is recorded for each day in thousand dollars.
1 | |
-
Book Size
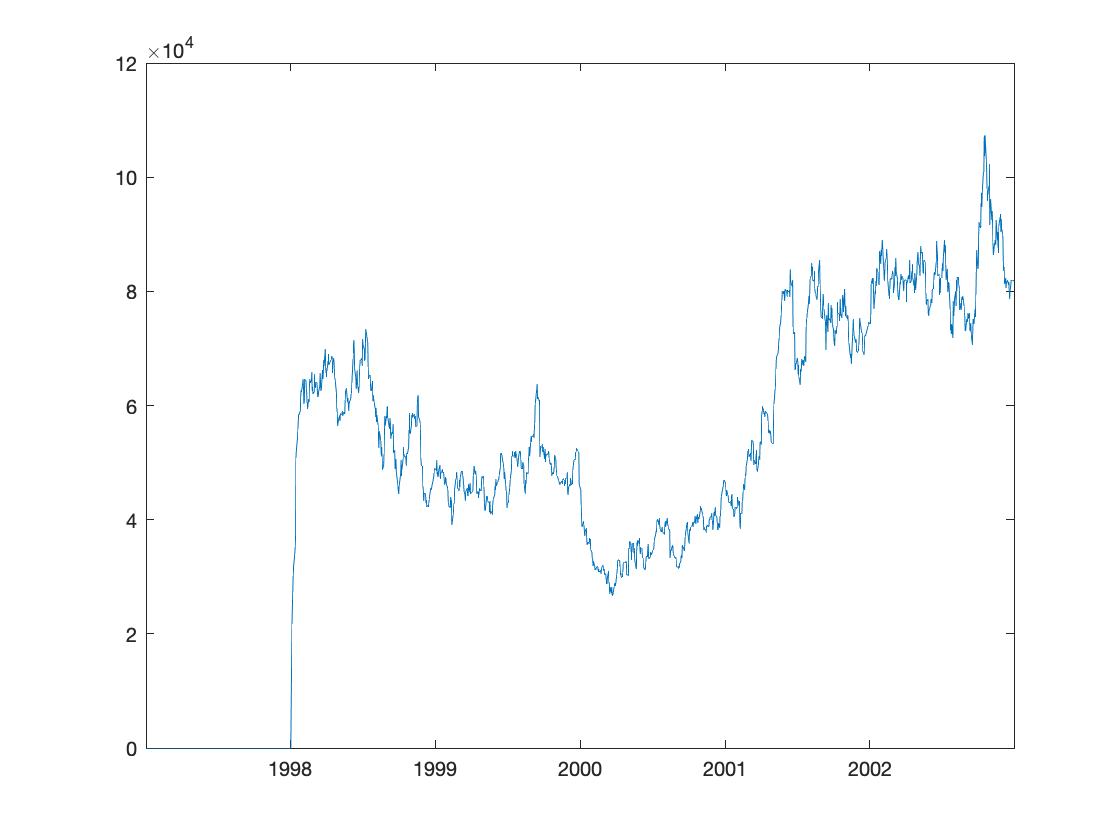
-
Trade Size
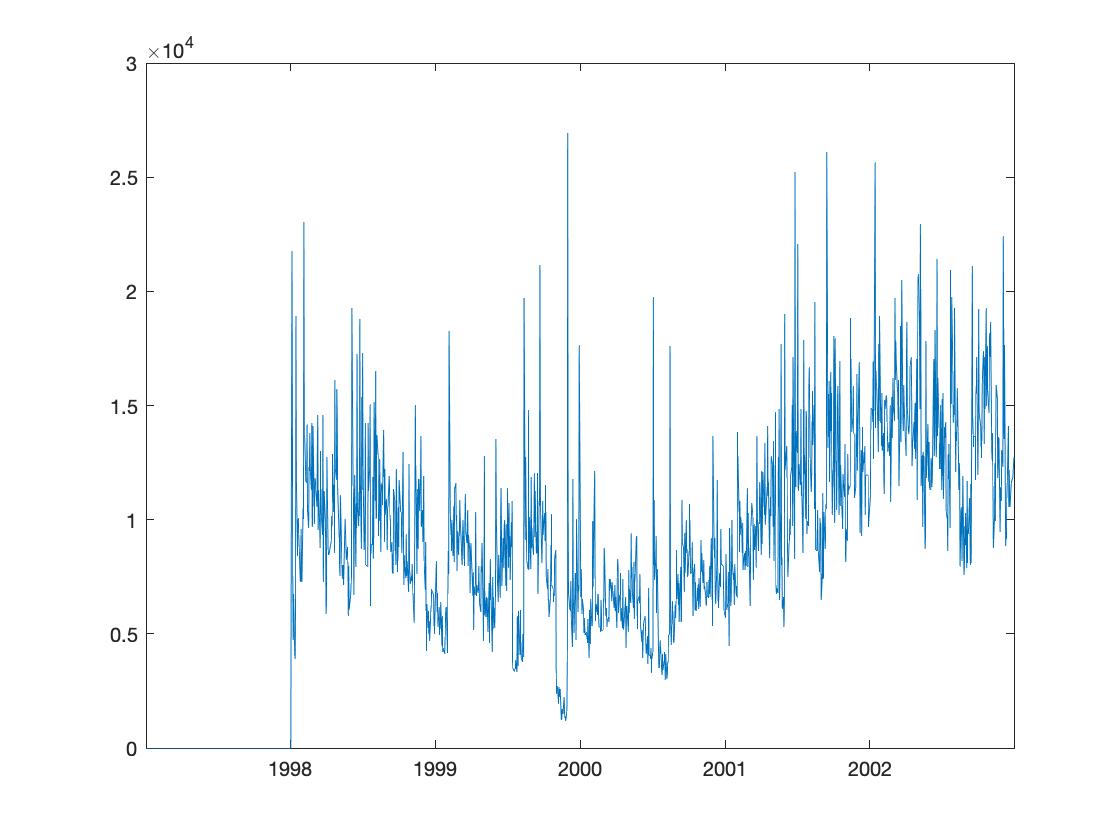
-
Profit & Loss
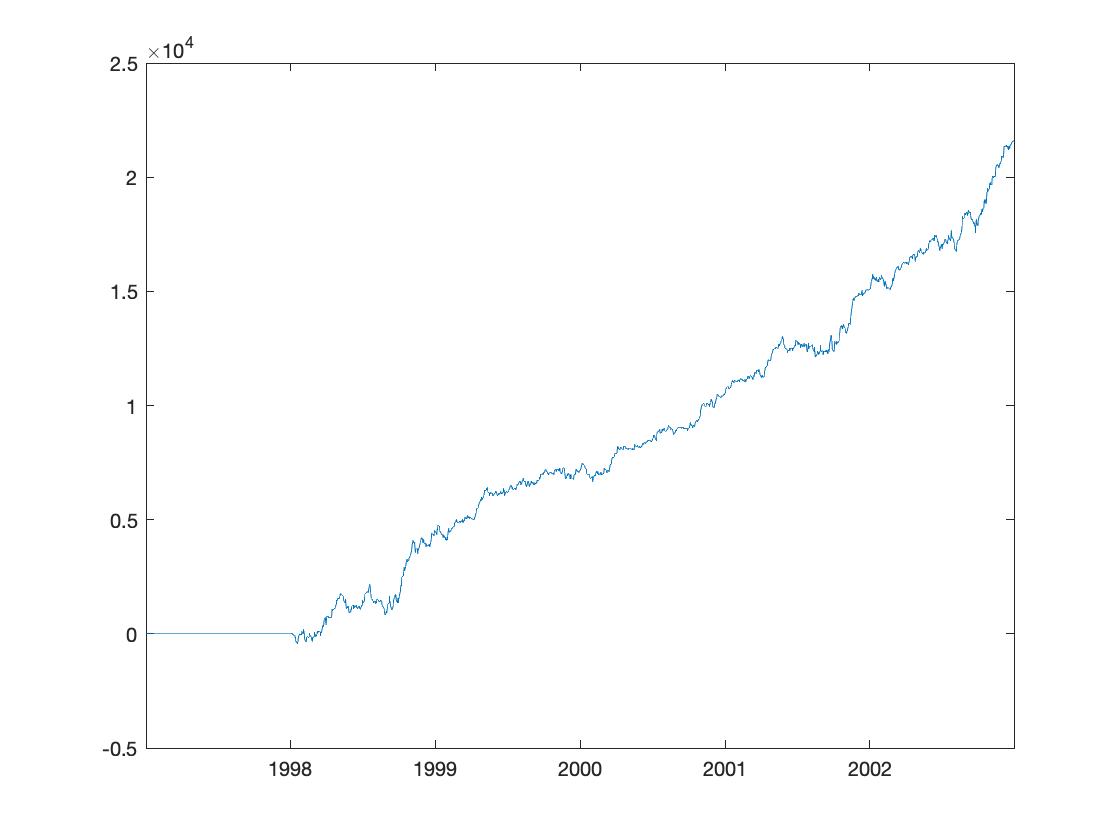
Performance Gauge
I calculated the Sharpe ratio, the maximum drawdown and the deepest drawdown for the performance of the portfolio. The Sharpe ratio is recorded as 2.640 for the long-short portfolio. And the longest drawdown is 29 days with $1.336M depth.
1 | |